项目开发大致流程
1. 摘要
2. 项目要求
3. 总体设计
4. 结果演示
5. 项目配置
6. 项目源代码
1. 摘要
本次课程的三级项目是要求设计实现一个管线铺设辅助系统,设计算法并实现使铺设的输水管道距离最短。
本项目主要应用了最小生成树算法:
prime算法和Kruskal算法两种算法,具备从文本读取数据、显示最佳铺设方案,以及绘制最佳方案的简单示意图等功能,以东校区各建筑物为例,实现了获得任意两个建筑物之间铺设管道的最佳方案。
关键词:【最小生成树】 【prime算法】 【kruskal算法】
2. 项目要求
用最小生成树算法实现东区各建筑之间铺设的输水管道距离最短,需要满足如下要求 :
(1)将管线经过的建筑物以及建筑物之间的距离,抽象成无向图,并以矩阵的形式表示,并保存在文本中,
系统通过读取文本的方式,获取该矩阵;
(2)从Prim算法和Kruskal算法中至少选择一种实现管线铺设的最优方案,系统可以最优方案
的生成过程,并且可以文本的形式输出;
(3)在系统上可以生成最优方案的简易图。
3. 总体设计
3.1 大致划分
总体上将项目划分为前端和后端两个层面:
|— 前端: 主要负责展示良好的界面, 增强交互性
|— 后端: 主要负责实现项目的功能
(1) 项目类型:
javaWeb项目 (Servlet+Jsp)
(2) 开发工具:
MyEclipse + MySQL + Navicat
(3) 前端界面的实现:
通过 html + css + css3 + js + jquery 来实现
1. 项目结果页面展现

web.xml:
用于配置View层中Servlet服务器的信息和路径
index.jsp:
用于显示项目主页的页面
kruskalPage.jsp:
用于显示Kruskal算法处理结果的页面
pirmePage.jsp:
用于显示Kruskal算法处理结果的页面
showScenery.jsp:
用于显示周边建筑物信息的页面
map.jsp:
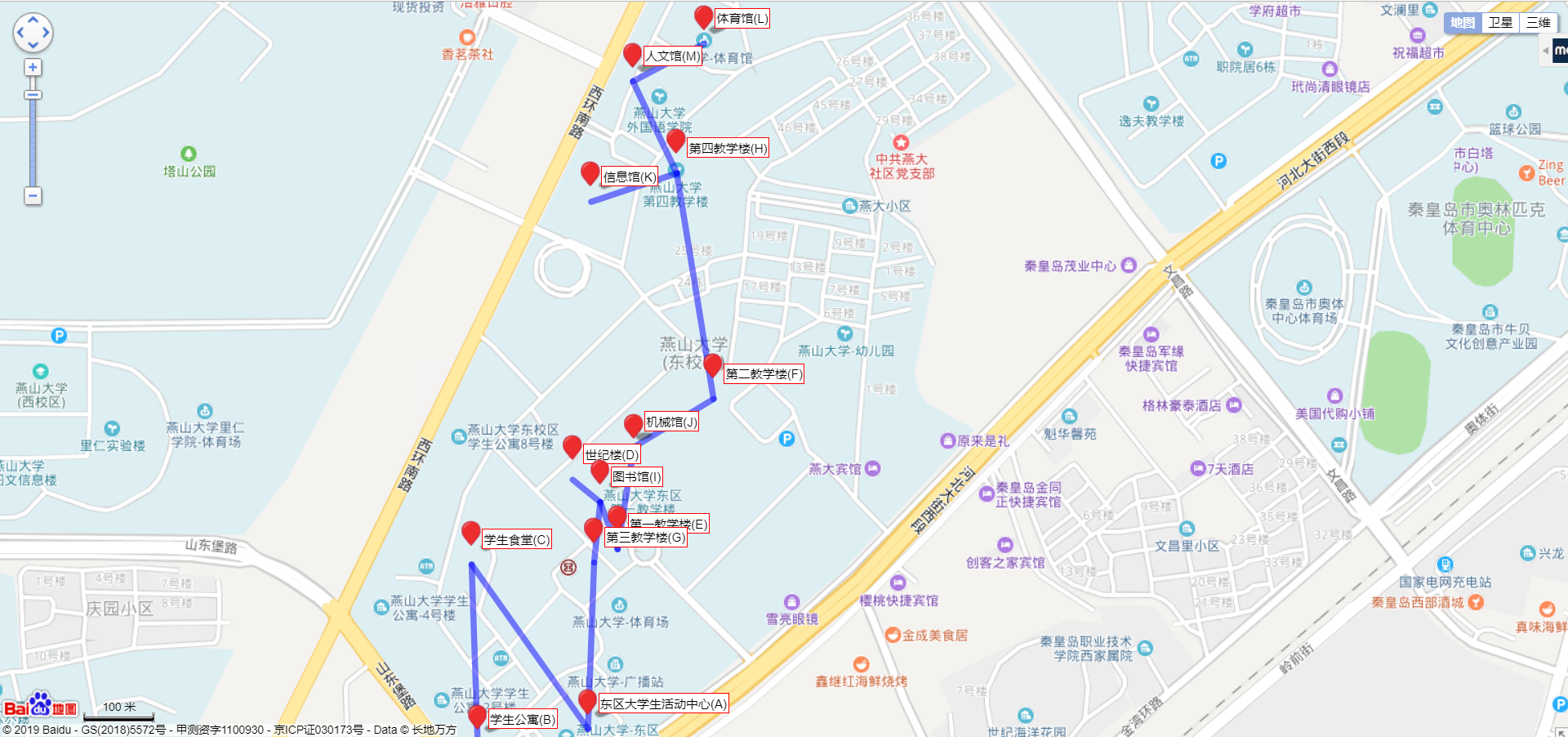
实现了简易图的绘制(引入百度地图api, 从后台传入经算法处理后的数据生成)
(4) 绘制简易图功能的实现:
引入百度地图api, 从后台传入经算法处理后的数据,然后生成对应最短路线
3.2 算法的实现:
1. 算法所用数据结构选型
所用矩阵: n*2矩阵
选择原因:方便hashMap的存取。
存放矩阵内信息所用数据结构:hashMap
选择原因:
letCode中有一道返回两数之和的算法题,通过条件遍历查询数组即可获得完成,但是官方推荐的是用hashMap存取并遍历,经过letCode上的大量数据测试,得出在这种情况下hashMap的执行效率更高,所用时间更少,通过分析两算法,得知都要按条件查询矩阵内容,所以对于这种规模的数据和相似的情况,我们采用hashMap来存取数据。
存放无向图结点的数据结构: Set集合
选择原因:
集合具有元素无序不重复的特性,所以用来存放结点可以防止其重复出现。
路径返回结果所用数据结构: ArrayList
选择原因:
ArrayList具有有序便于插入删除的特点,方便对结果进行后续的整理和修改。
2. 算法的具体实现
Prime算法部分主要由PrimeServiceImpl实现
kruskal算法部分主要由kruskalServiceImpl实现
CaculateUtil.java :提取并封装了PrimeServiceImpl 和 KruskalServiceImpl算法用到的方法
2.1 实现Prime算法的基本思想:
- 清空生成树,任取一个顶点加入生成树
- 在那些一个端点在生成树里,另一个端点不在生成树里的边中,选取一条权最小的边,将它和另一个端点加进生成树
- 重复步骤2,直到所有的顶点都进入了生成树为止,此时的生成树就是最小生成树
2.2 Prime算法适用性和时间复杂度:
Prime算法求最小生成树时候,和边数无关,只和定点的数量相关,所以适合求稠密网的最小生成树,时间复杂度为O(n×n)
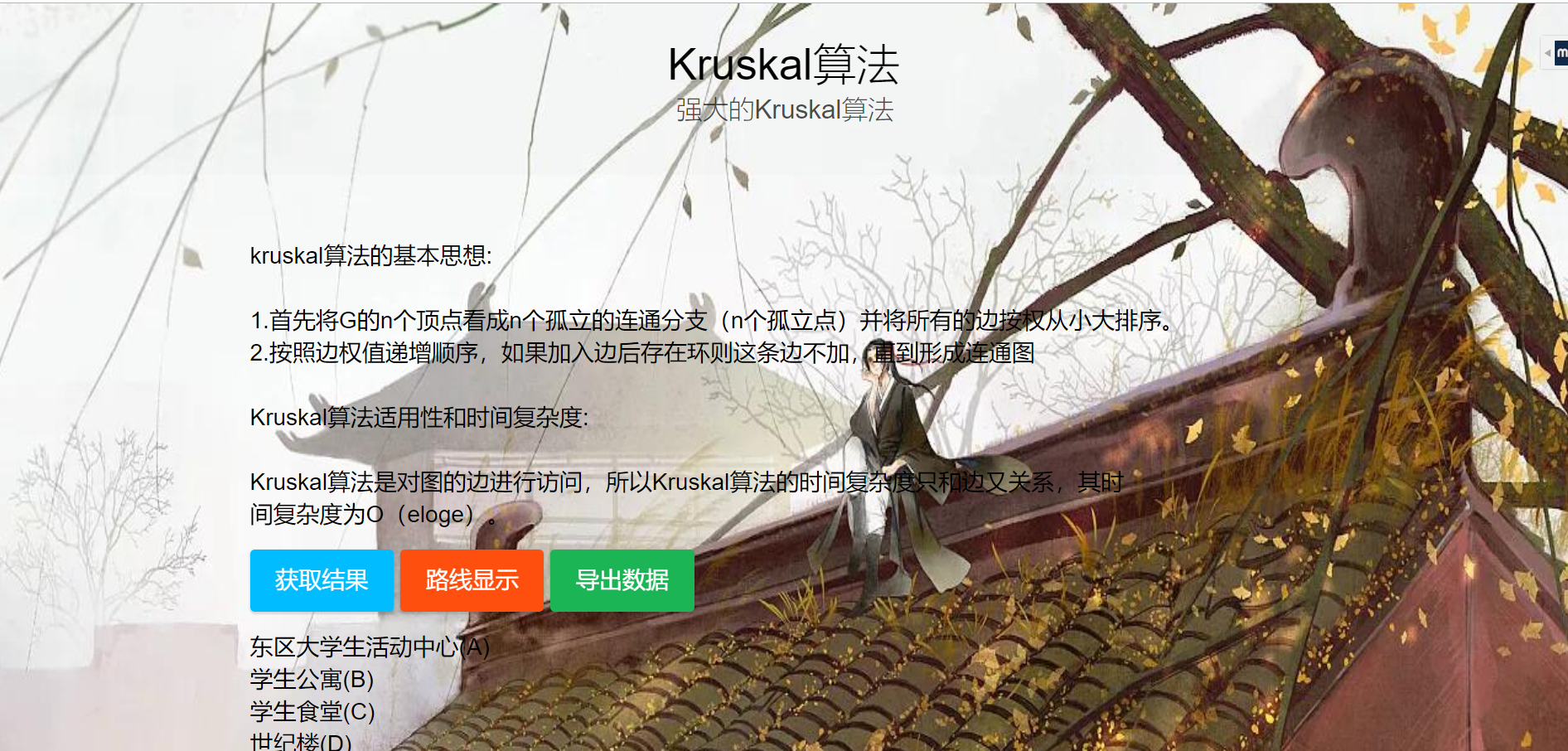
2.3 实现Kruskal算法的基本思想:
- 首先将G的n个顶点看成n个孤立的连通分支(n个孤立点)并将所有的边按权从小大排序。
- 按照边权值递增顺序,如果加入边后存在环则这条边不加,直到形成连通图
2.4 Kruskal算法适用性和时间复杂度:
Kruskal算法是对图的边进行访问,所以Kruskal算法的时间复杂度只和边又关系,其时间复杂度为O(eloge)
4. 结果演示
4.1 项目主要界面展示
首页

节点信息展示

Prime算法界面

Kruskal算法界面
最终生成的路线图
4.2 项目运行演示
以下两个地址都可
腾讯云对象存储COS视频地址:
https://video-1254265973.cos.ap-beijing.myqcloud.com/arithmetic.mp4
哔哔哩哔哩视频地址:
https://www.bilibili.com/video/av40697433/
5. 项目配置
5.1 矩阵文件格式
矩阵文件的格式应为N*2矩阵, 形式如 AB 150 。 A, B 为结点的编号, 150为两结点结点间的距离。
详细配置可参照项目中的ReadDatas.txt和ReadDatas3.txt。
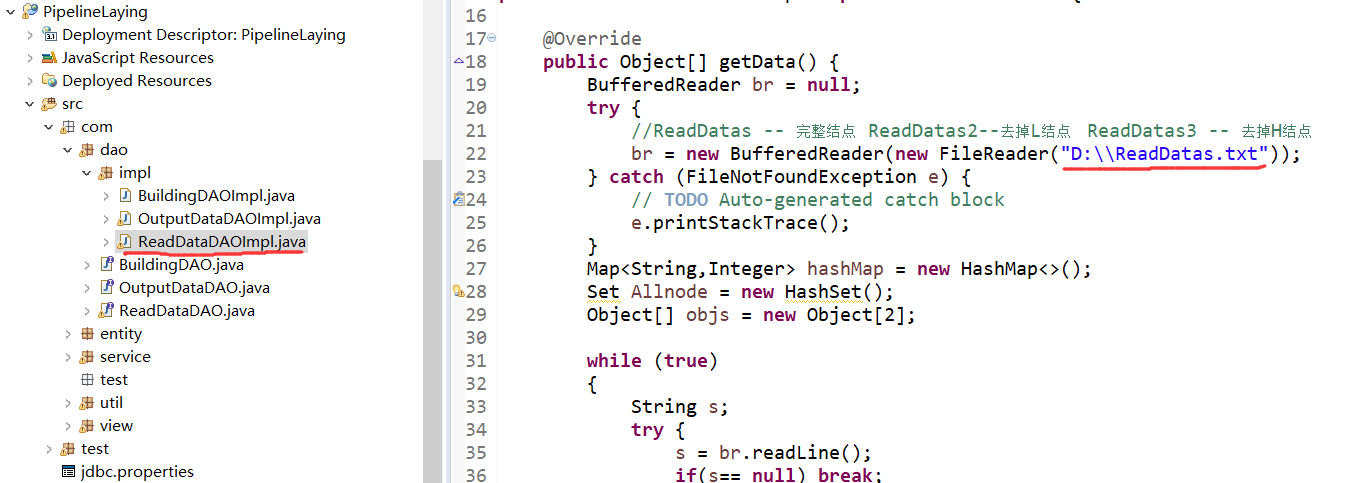
5.2 读入文件路径的设置
读入文件的路径设置在 PipeLineLaying/src/com/dao/impl/ReadDataDAOImpl.java 里面修改,
修改位置为下图标红线的地方:
5.3 输出文件路径的设置
输出最终结果的路径设置在 PipeLineLaying/src/com/dao/impl/OutputDataDAOImpl.java 里面修改,
修改位置为下图标红线的地方:

5.4 数据库配置
(1) 数据库连接信息可在项目下的 src/jdbc.properties 文件中修改,
下图标红线的位置对应的是 自己数据库的名字(类型为Mysql数据库)。
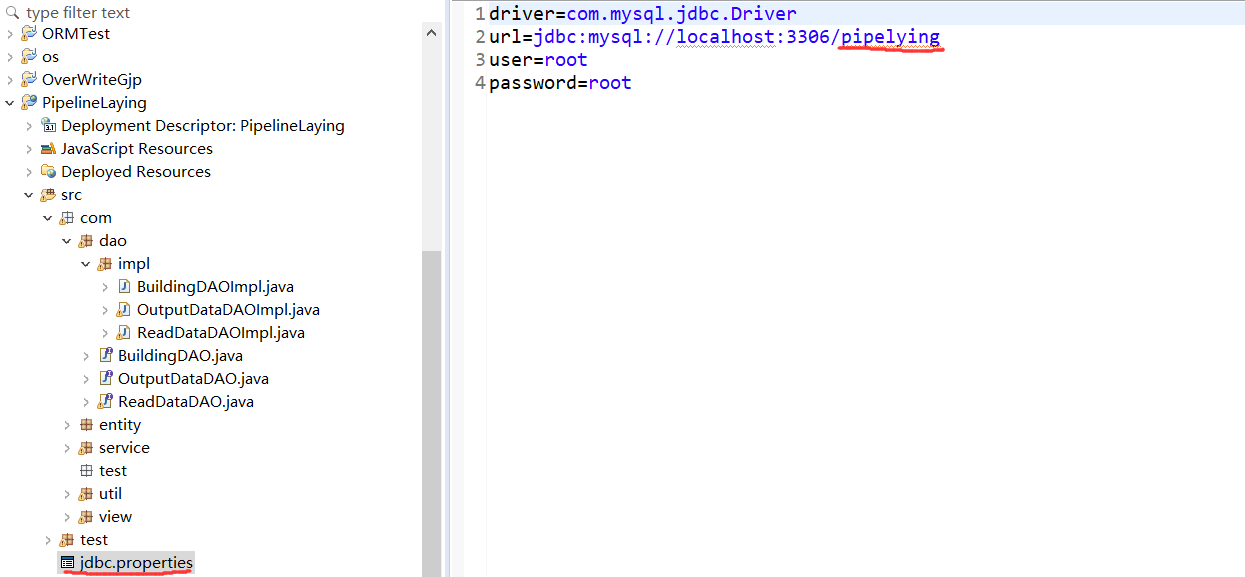
(2) 将项目中的 pipelying.sql 导入自己电脑的本地数据库
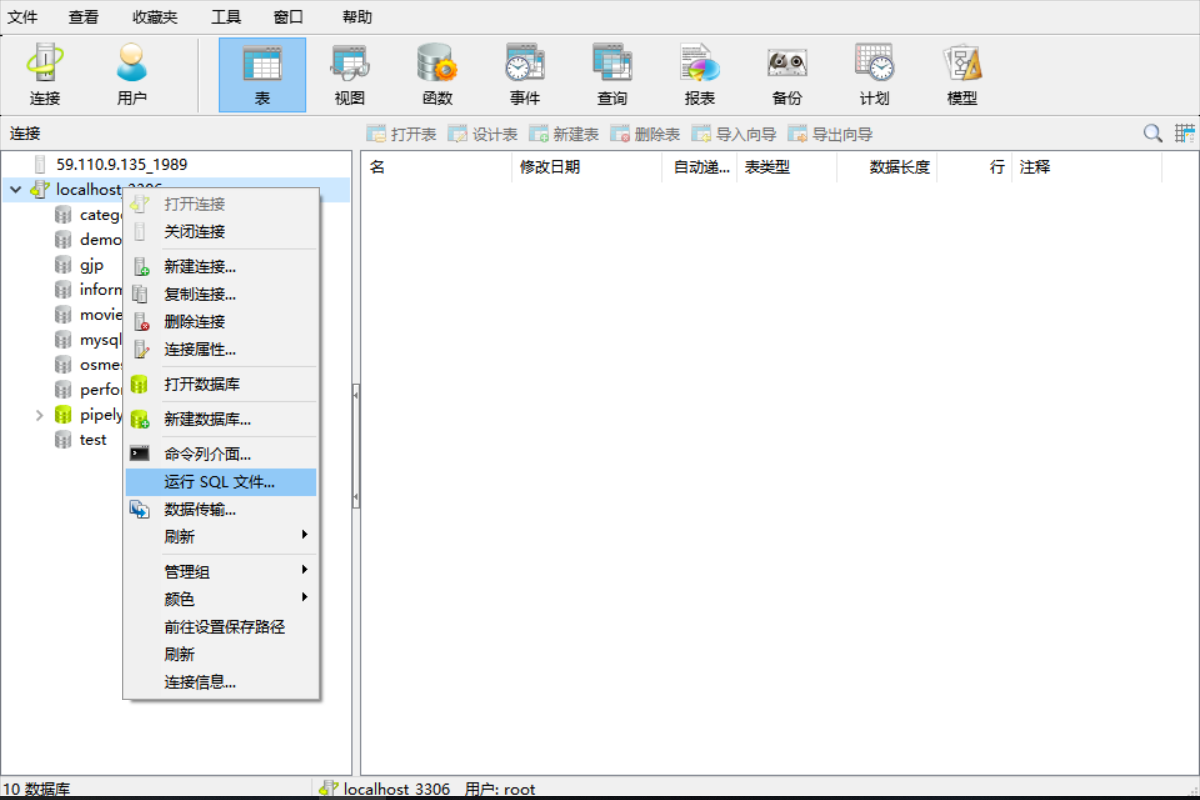
演示Navicat导入的方式:
右键连接–>选择运行SQL文件–>选中pipelying.sql–>运行完毕点击关闭–>右键刷新。
完成以上步骤后, pipelying数据库便成功导入到了你的本地数据库中。
6. 项目源代码
百度网盘下载 ( 包含项目报告 )
- 百度网盘链接: 链接:https://pan.baidu.com/s/1FQU3OHlm9E7IU9_0DsJphQ
- 提取码:qi9m
github下载 ( 只含源代码 )
- github下载地址: https://github.com/fyf2016/PipelineLaying.git
注: 两个地址都可以下载



